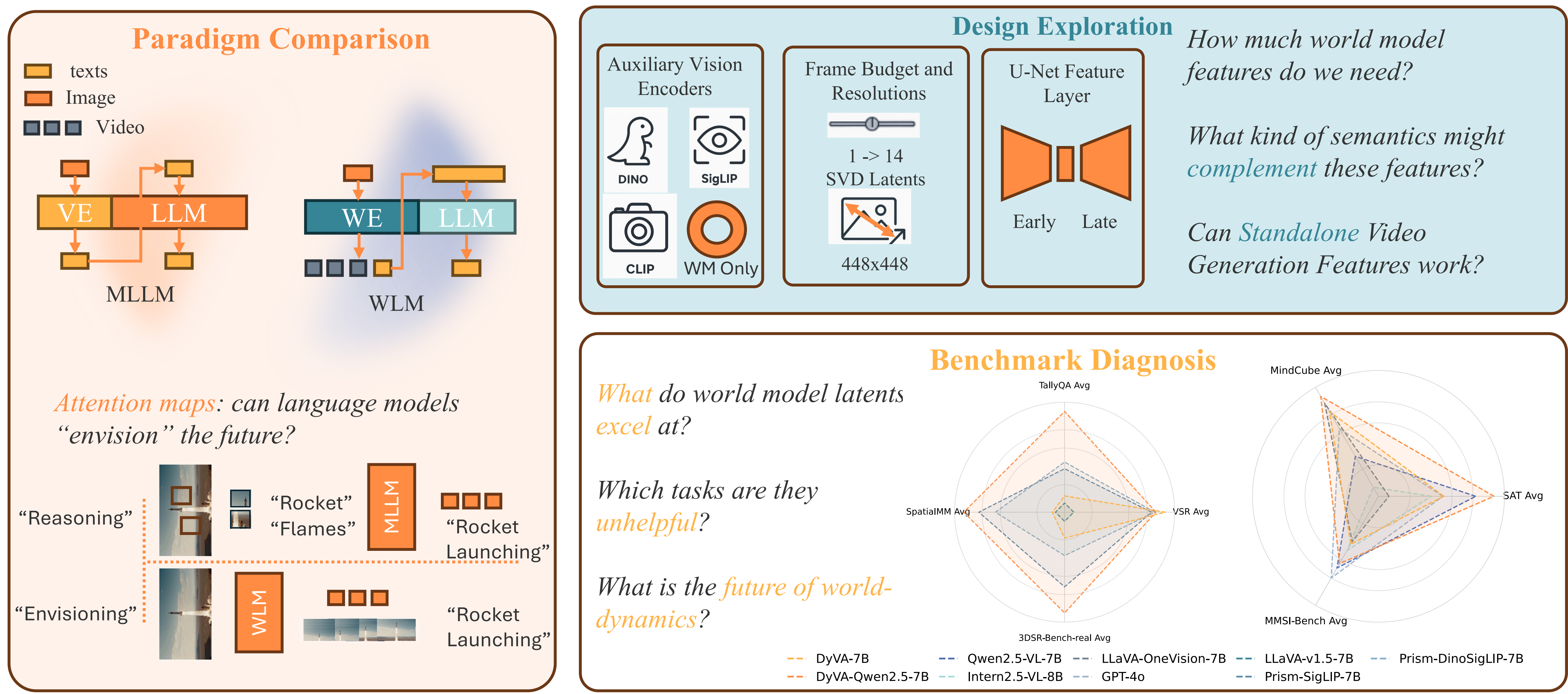
Trained on internet-scale video data, generative world models are increasingly recognized as powerful world simulators that can generate consistent and plausible dynamics over structure, motion, and physics. This raises a natural question: with the advent of strong video foundational models, might they supplant conventional vision encoder paradigms for general-purpose multimodal understanding? While recent studies have begun to explore the potential of world models on common vision tasks, these explorations typically lack a systematic investigation of generic, multimodal tasks. In this work, we strive to investigate its current capabilities, when these priors are transferred into a Vision-Language Model (VLM): we re-purpose a video diffusion model as a generative encoder, queried for a single denoising step, and treat the resulting latents as an additional set of visual embeddings. We empirically investigate this class of models, which we refer to as World-Language Models (WorldLMs), and we find that generative encoders can indeed capture latents useful for downstream understanding, showing distinctions from conventional vision encoders. Naming our best-performing variant Dynamic Vision Aligner (DyVA), we further discover that this method significantly enhances spatial-reasoning abilities and enables single-image models to perform multi-frame reasoning.
Through the curation of a suite of visual-reasoning tasks, we find DyVA to surpass both open-source and proprietary baselines on out-of-domain tasks, achieving state-of-the-art or comparable performance. We attribute these gains to WorldLM's inherited motion-consistency internalization from video pre-training. Finally, we systematically explore extensive model designs to highlight promising directions for future work. We hope our study can pave the way for a new family of VLMs that leverage priors from world models and are on a promising path towards generalist vision learners. Our code is available at DyVA-WorldLM.
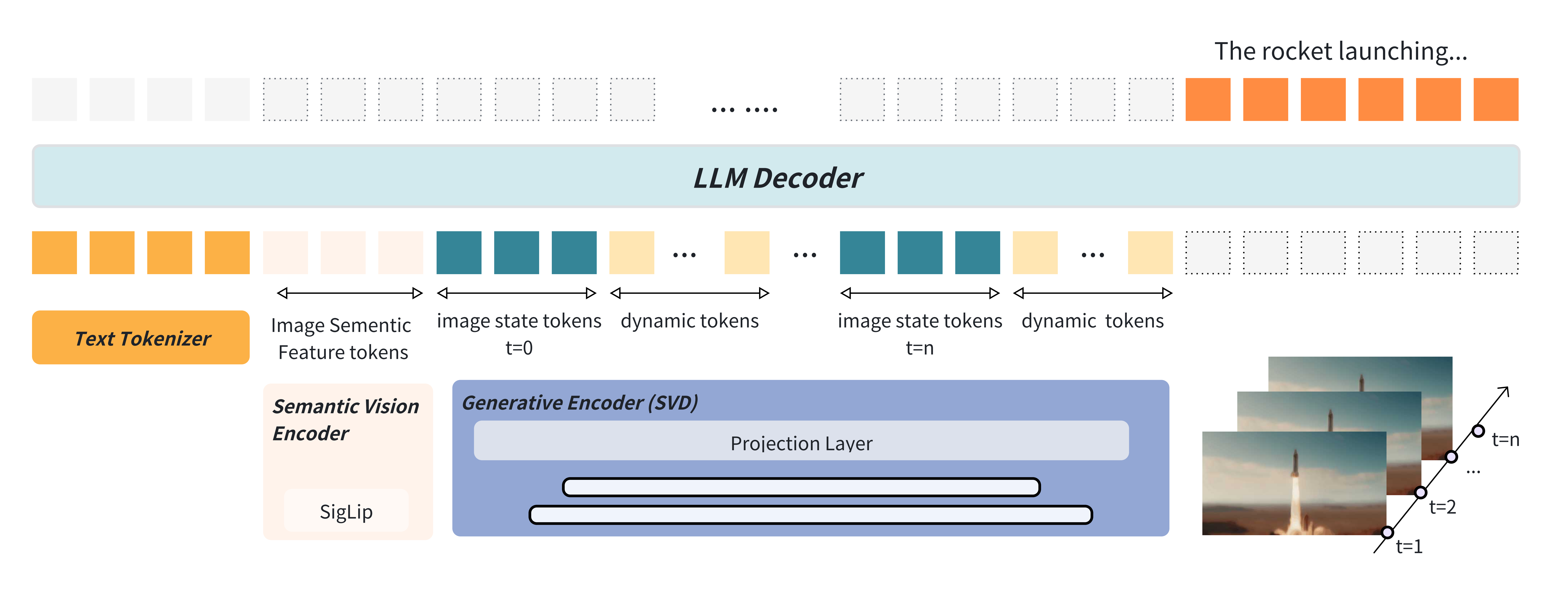
Our World-Language Model (WorldLM) framework introduces a new way of combining static and dynamic visual representations for multimodal reasoning. Unlike conventional VLMs, which rely solely on static image encoders, WorldLM integrates world-model priors learned from video generation. The pipeline works as follows:
This design allows the model to go beyond static description and instead envision future possibilities. We name the best-performing variant of this family of WorldLMs Dynamic Vision Aligner (DyVA).
We evaluate DyVA on a comprehensive suite of out-of-domain (OOD) benchmarks. DyVA, despite being trained only on single images, achieves state-of-the-art performance, surpassing strong baselines including GPT-4o.
Performance comparison on SAT Synthetic, MMSI-Bench, and MindCube. DyVA excels in these OOD tasks without multi-image training. Highest averages are in bold.
| Model | SAT Synthetic | MindCube | MMSI-Bench | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Obj Move. | Act. Seq. | Act. Cons. | Goal Aim | Persp. | Avg. | Rot. | Among | Around | Avg. | Cam-Cam | Obj-Obj | Reg-Reg | Cam-Obj | Obj-Reg | Cam-Reg | Means | Appr | Cam | Obj | MSR | Avg. | |
| Qwen2.5-VL-7B | 79.29 | 84.70 | 47.83 | 25.84 | 35.17 | 53.16 | 38.76 | 29.50 | 21.35 | 29.26 | 32.3 | 27.7 | 29.6 | 32.6 | 24.7 | 32.5 | 26.6 | 27.3 | 16.2 | 31.6 | 30.3 | 28.70 |
| Intern2.5-VL-8B | 77.74 | 55.49 | 53.74 | 15.03 | 32.61 | 48.06 | 18.68 | 36.45 | 18.20 | 18.68 | 24.7 | 24.5 | 24.7 | 25.6 | 29.4 | 26.5 | 25.0 | 18.2 | 20.3 | 39.5 | 25.8 | 25.90 |
| LLaVA-OneVision-7B | 71.10 | 21.64 | 49.85 | 31.76 | 35.43 | 43.24 | 36.45 | 48.42 | 44.09 | 47.43 | 20.4 | 33.0 | 29.6 | 29.1 | 25.9 | 30.1 | 29.7 | 25.8 | 18.9 | 34.2 | 11.6 | 24.50 |
| GPT-4o | 61.50 | 33.20 | 47.60 | 67.50 | 37.50 | 49.40 | 40.17 | 29.16 | 38.81 | 38.81 | 34.4 | 24.5 | 23.5 | 19.8 | 37.6 | 27.7 | 32.8 | 31.8 | 35.1 | 36.8 | 30.8 | 30.30 |
| DyVA-7B | 49.15 | 57.81 | 49.25 | 53.38 | 40.44 | 49.51 | 37.70 | 43.10 | 49.00 | 44.62 | 21.5 | 30.9 | 25.9 | 31.4 | 27.1 | 20.5 | 35.9 | 24.2 | 13.5 | 19.7 | 24.2 | 24.90 |
| DyVA-Qwen2.5-7B | 78.83 | 62.13 | 49.85 | 51.86 | 41.72 | 55.24 | 37.20 | 39.10 | 51.70 | 49.80 | 15.1 | 33.0 | 25.9 | 33.7 | 35.3 | 30.1 | 32.8 | 25.8 | 17.6 | 27.6 | 29.3 | 28.00 |
Performance on VSR, TallyQA, SpatialMM-Obj, and 3DSR-Bench-real. DyVA surpasses all baselines in zero-shot inference. Highest values are bolded.
| Models | Data | VSR | TallyQA | SpatialMM-Obj | 3DSR-Bench-real | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Topo. | Prox. | Proj. | Direc. | Adj. | Orien. | Unall. | Avg. | Avg. | 1-obj | 2-obj | Avg. | H. | L. | O. | M. | Avg. | ||
| LLaVA-v1.5-7B | 558k+665k | 52.24 | 50.00 | 54.77 | 50.00 | 50.86 | 48.98 | 57.50 | 52.94 | 58.74 | 57.37 | 44.87 | 48.91 | 55.42 | 57.82 | 26.09 | 39.42 | 45.02 |
| Prism-SigLIP-7B | 665k | 67.48 | 62.50 | 65.63 | 66.67 | 55.17 | 55.10 | 67.50 | 64.97 | 62.25 | 62.54 | 46.77 | 51.86 | 52.28 | 60.22 | 27.23 | 42.17 | 46.55 |
| Prism-DINOSigLIP-7B | 665k | 71.34 | 59.38 | 65.63 | 64.29 | 53.45 | 48.98 | 52.50 | 65.46 | 62.93 | 58.56 | 47.72 | 51.22 | 56.85 | 59.42 | 27.23 | 38.97 | 45.82 |
| DyVA-7B | 665k | 68.90 | 68.75 | 66.74 | 66.67 | 66.38 | 61.22 | 57.50 | 67.10 | 59.47 | 54.78 | 46.29 | 49.03 | 53.71 | 57.60 | 27.23 | 40.80 | 45.41 |
| DyVA-Qwen2.5-7B | 665k | 66.67 | 71.88 | 68.74 | 61.90 | 62.93 | 40.82 | 55.00 | 65.63 | 68.11 | 62.74 | 47.53 | 52.44 | 52.57 | 54.51 | 27.23 | 49.60 | 47.16 |
@misc{zhang2025worldmodelsbenefitvlms,
title={Can World Models Benefit VLMs for World Dynamics?},
author={Kevin Zhang and Kuangzhi Ge and Xiaowei Chi and Renrui Zhang and Shaojun Shi and Zhen Dong and Sirui Han and
Shanghang Zhang},
year={2025},
eprint={2510.00855},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.00855},
}